
As a software developer, you learn the importance of refactoring early on. You often hear buzzwords like “reducing code complexity” and “increasing usability”. But what’s the right approach?
While it’s obvious that refactoring is important, the end goal can be vague. You need to know why you’re doing it and have a clear strategy when undertaking that task.
Wrong reasons for refactoring code
First, let’s cover the wrong reasons to refactor.
Decomposition for decomposition’s sake
Starting out, I thought that refactoring mainly came down to keeping my functions and classes small. I believed that’s all it took to make my code better.
But that’s not the case.
That’s called decomposition for decomposition’s sake and does nothing to improve your code. Let’s take a look at this example:
|
|
This is a huge function, surely I could improve it just by splitting it up. Right? Let’s try that:
|
|
processInventory is smaller now, and the code does look cleaner at first glance. However, in terms of decoupling, it’s not a whole lot better than what we had before. You can’t easily reuse this code.
Our class is still missing the essential attributes of a good code: predictable, reusable, and testable. We’ll break down these attributes and will come back to refactoring the code above the right way.
Closet analogy
You could also go too far with your refactoring work. You could end up creating an unnecessarily thick layer of abstractions that actually hurts the readability of your code.
A good analogy to this is organizing a closet. If you dump all of your clothes on the floor, it’s a mess. If you take the time to separate your shirts, pants, and shoes neatly, your closet is in much better shape and you can find things easier.
But, if you keep going and try to find a distinct spot for each item in your wardrobe, you will spend hours clearing your closet, and the result will not be much better than the mess you started with in the first place.
So try to avoid abstracting and splitting your code just for the sake of keeping it small.
The question then is, why SHOULD you refactor? I believe pragmatic refactoring has two goals:
- Decoupling code
- Code cohesion
Decoupling code
As mentioned before, decoupled code has three main attributes:
- It’s predictable
- It’s testable
- It’s reusable
Predictable code
Predictable code will always return the same output given the same input. It’s agnostic to any external changes. If we’re talking specifically about functions, predictable functions are also called pure functions.
A simple way to make a function pure is to remove any inner state mutation using
dependency injection.
Let’s take a look at the requestInventory method we wrote earlier:
|
|
In our function, we’re mutating the outer state by reassigning this.inventoryItems. That’s a side effect and should be avoided as it makes our function less predictable. Let’s make this function pure by providing inventoryItems as a parameter instead:
|
|
The fix is trivial but important nonetheless - the worst code smells are often the simplest to fix.
To learn more about dependency injection in the context of Node applications, check out my post here.
Testable code
This attribute goes along with predictability as you can’t test unpredictable code.
With any project, it’s important to have strong test cases to fall back on. Yet people often avoid it, oftentimes because they realize that their code is difficult to test.
That’s why as you write your code, you should ask yourself: “How easy will it be to write a test case this code?” And if you think it will be hard to test the function you wrote, refactor it.
Reusable code
Now let’s talk about reusability.
The North star for writing resuable code is the single responsibility principle . It simply means that your functions should be designed to do one thing. Here’s an example:
|
|
processInventory is currently doing two things: showing the loader and processing the request. In its current state, this function is not very reusable. So let’s split it up:
|
|
This is better. The important piece of processInventory is now in a updateInventories method and can be reused.
Code cohesion
Now let’s cover the code cohesion in your project.
Feature cohesion
At a high level, any application is just a set of distinct features put together. Not all of them have a connection to each other. In fact, a lot of them don’t.
That’s why I believe it’s better to group code around specific feature before grouping by functionality. Let me explain what I mean.
Say you’re developing React application with three different pages: Dashboard, Settings, and Authentication. Each of the pages has reducers, actions, components, containers, and utility methods.
I suggest you structure your code and files around the main pages first. So here’s what the project structure might look like:
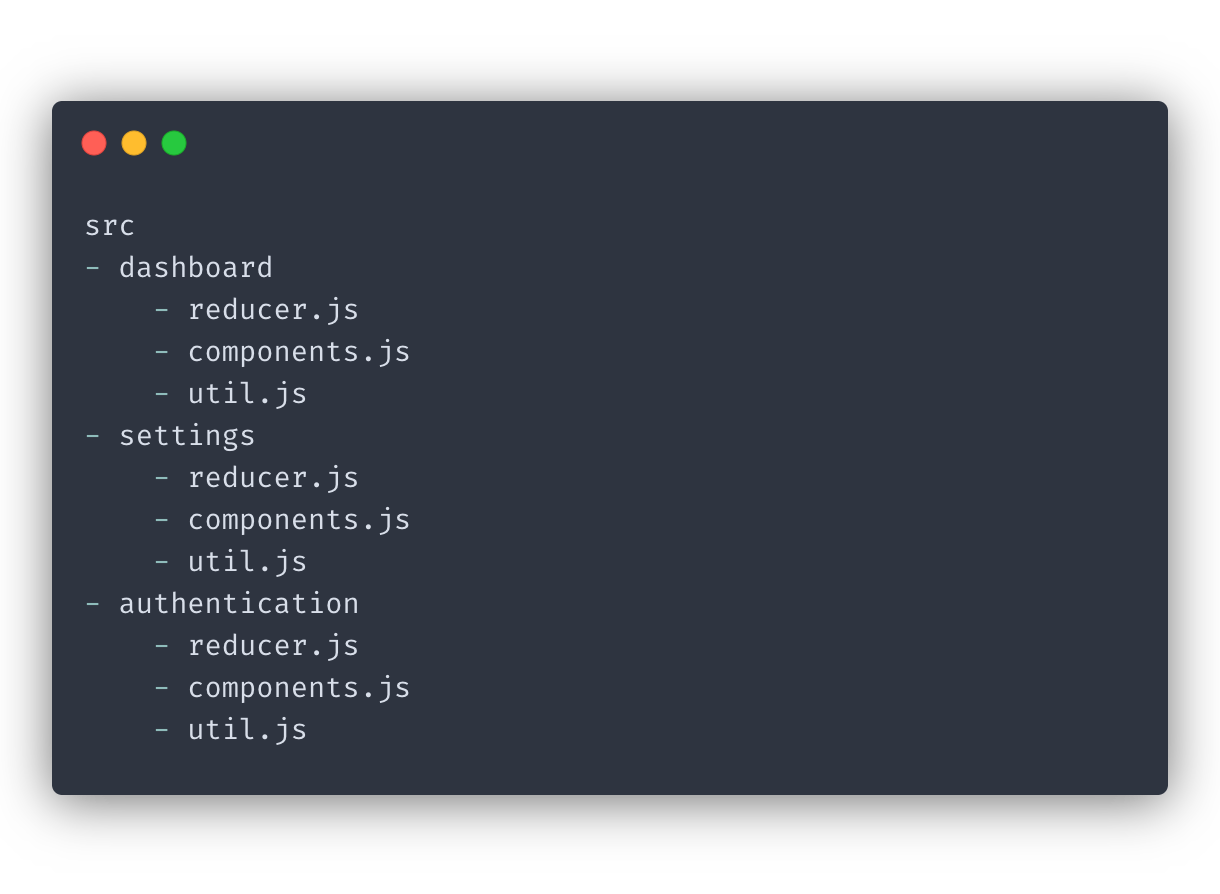
The benefit of structuring your code this way is that it’s geared towards your typical workflow. You’ll rarely find yourself working on multiple different features at once. Usually, we focus on one at a time. And it’s much less of a mental effort to switch between the files if they’re all within the same folder.
Functional cohesion
After grouping your code by features, you can start grouping some of it by functionality.
Not all of your code needs to be grouped this way. The candidates for this grouping are pieces of code used in multiple places and not tied to a specific feature. It’s a code that you are confident you will continue to reuse. Some of the examples are application-wide utility methods, API request clients, and interfaces.
If starting a project from scratch, you could start grouping your code based on the features and the functionality at the same time.
Hopefully this post shed some more light on the end goal behind refactoring.
If done correctly, refactoring is a good exercise that will help to scale your codebase and maintain its quality.
If you’d like to get more web development, React and TypeScript tips consider
following me on Twitter,
where I share things as I learn them.
Happy coding!