One of the signs of quality software is how well it can scale. In our days of cloud, computing scalability is especially important. Thanks to modern cloud providers, there’s a myriad of ways to scale your application. Let’s talk about one useful model to keep in mind when scaling - Scaling Cube.
In the book “ The Art of Scalability “, the authors suggest an ingenious model to represent different categories of software scaling called “Scaling Cube”. In this post we’ll go over the basic principles behind the model and why you should consider it when scaling your project.
3 axises of the Scaling Cube
Take a look at this diagram:
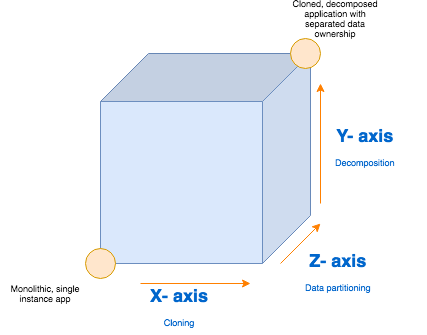
The diagram above indicates the Scaling Cube. The bottom left corner indicates an application that has not yet undergone any of the scalability improvements. On the other hand, the top right corner indicates an application that has been through all three categories of scalability improvements. Usually you want to aim for the top right corner, however that can also depend on your application’s business requirements.
Here’s what the 3 axises indicate:
- X- axis: Creating cloned application instances
- Y-axis: Decomposing into micro-services by functionality
- Z-axis: Splitting using data ownership
Now let’s break down the axises in more details.
X-axis: Cloning
This axis is more or less self-explanatory. When thinking about improving your application’s load handling, the first thing you should consider is spawning multiple instances of your application and distributing the load across them equally.
Scaling your application with X-axis is much faster and requires less effort than the other two categories. Nowadays, spawning additional instances of your application is usually a cheap and fast way to scale your project.
Scaling with X-axis can be done in two ways.
- Vertical balancing – adding more resources to a single machine.
- Horizontal balancing – adding more machines to the infrastructure.
Vertical balancing
In this scenario you utilize the unused computing resources of the single machine that your application runs on. You can accomplish this by instantiating multiple worker processes that all run a separate instance of your application. However, keep in mind that to handle these worker processes efficiently, you need to use some kind of load balancing mechanism.
You can setup vertical balancing quite easily in Node.js using NPM packages like cluster.
Horizontal balancing
The second type of balancing is horizontal balancing. This simply means adding more machines that run your application to your infrastructure. This can be easily achieved and most of the smaller steps will be taken care of for you by your cloud provider. AWS and other cloud providers also allow you to dynamically scale the number of machines based on the amount of traffic.
Most of the time, cloud providers setup a separate server for a reverse proxy, such as Nginx, which also acts as a load balancer for your instances.
Other benefits of multiple instances
Adding multiple instances can definitely improve the responsiveness of your application by making it faster, but it has other benefits to it as well:
- It makes your application more fail-proof: even if one of your instances unexpectedly crashes, the other instances are still there to take care of the load.
- If it’s crucial for you to implement a zero down-time policy, then adding multiple instances is a must. For example, when making an update, you can avoid any down-time by applying changes to your instances one by one.
If you wish to make the most of your resources to improve your application’s load handling, you should consider exploiting both vertical and horizontal balancing at the same time.
Y-axis: Decomposition
Simply put, Y-axis refers to the practice of splitting your single monolithic application into multiple standalone microservices based on their functionality. This practice is becoming widely adopted with the rise of the serverless technology. And for a good reason too, adopting serverless architecture provides a lot of benefits.
Microservice architecture improves your load handling since multiple stand-alone services provide more computing power over the single monolithic application. You can improve on that further by applying X-axis improvements to your services as needed.
The architecture of your application also improves when you split it into smaller independent pieces. Because in doing so, your are almost forced to created a loose coupling between them.
Having multiple services also makes your application more robust and fail-proof since failure of one service won’t necessarily jeopardize the performance of the other. Compare that to monolithic architecture where if one part of the app crashes without being properly handled, the whole instance will go down.
Today, thanks to the rise of microservice architecture, almost any cloud provider provides a support for serverless computing including AWS’s Lambdas, Google’s Cloud functions and Azure’s functions.
Z-axis: Data partitioning
Applying X and Y axises should suffice for most business applications. However, if you have a big enterprise application and the robustness of it is a very high priority, you can improve on your infrastructure’s setup further with Data partitioning. Note that you should only consider Data partitioning when you’ve applied the X and Y axis improvements the fullest.
Data partitioning is the third and the last scalability category and is mostly applicable to the databases. When considering load handling you also need to consider the capabilities of your database.
Most of the time you are able to separate your application’s data in multiple smaller databases based on some attribute. The exact attribute will depend on your business requirements but usually others split based on the alphabetical ordering of the records, the geographical region of the data and etc.
Data ownership
This concept goes along with microservices. The idea is to make your services independent from each others’ data. This can be achieved by making each service exclusively in charge of its own data. One way to do that would be to provide a separate database for each service and make it only accessible by that service. If other parts of your application need to retrieve the same data, they would have to communicate with your microservice instead. In doing so, you will reduce the amount of errors based on the data dependence.
And that’s it for this post!
Whether or not you were aware of the Scaling Cube before, you have most likely encountered the scalability techniques discussed in this post. Still, It’s helpful to know about this concept and consider it when trying to scale your application.
If you’d like to get more web development, React and TypeScript tips consider
following me on Twitter,
where I share things as I learn them.
Happy coding!