
Intro
Apollo is a popular GraphQL client with lots of features. You can use it for both fetching data as well as state management. Apollo has a robust caching mechanism. When used correctly, it can drastically improve the performance of your application by reducing the number of API requests you make.
Let’s see how Apollo handles cache normalization and cover some tips that will help you take full advantage of it.
What is cache normalization?
Normalization refers to the practice of reducing redundancy. In databases, reducing redundancy means reducing the amount of duplicate data by adjusting the structure of your database.
With Apollo, cache normalization means using cache to reduce the number of duplicate API requests. Instead of making the request, the Apollo client can return matching data from the cache.
How does Apollo perform cache normalization?
Let’s briefly cover how cache normalization works.
Under the hood, the Apollo client uses a JavaScript object with key-value pairs to store cached data. This object is flat, which makes fetching data from the cache almost instant.
Whenever you send a query, Apollo checks to see if that data already exists in the cache. If it does the client, will instantly return cached data, preventing a redundant API request.
Apollo adds new data to the cache by saving responses from queries and mutations, as long as the returned data has a valid format. Also, whenever the cache is updated, all of the parts of the UI that rely on Apollo’s data will automatically re-render and reflect the new data.
To be able to save data in the cache, your response needs to contain a unique identifier. This identifier, together with the __typename field, is used as a key within the cache object like so: __typeName + id. By default, Apollo looks for the id field, but you can
adjust the unique identifier key
when configuring the cache object.
Operations Apollo can and cannot cache
Not all Apollo operations are made equal. Some of them can be automatically cached by Apollo, given that they return valid data, while others must be handled manually.
Here’s the list of the operations Apollo can automatically cache:
- Queries
- Mutating a single object
- Mutating a set of the objects
Here’s the list of operations Apollo cannot cache:
- Adding data
- Deleting data
Apollo doesn’t know when you want your application to reflect adding or deleting data. In those cases, you can either manually alter cache or refetch updated data using a new query.
Tips for better cache normalization
Now let’s cover the tips that will help you take full advantage of Apollo’s automatic cache normalization.
Always return the id for queries
As I mentioned before, Apollo requires a unique identifier to use as a key, so a good rule of thumb is to always return the id field for any of your queries that you want cached.
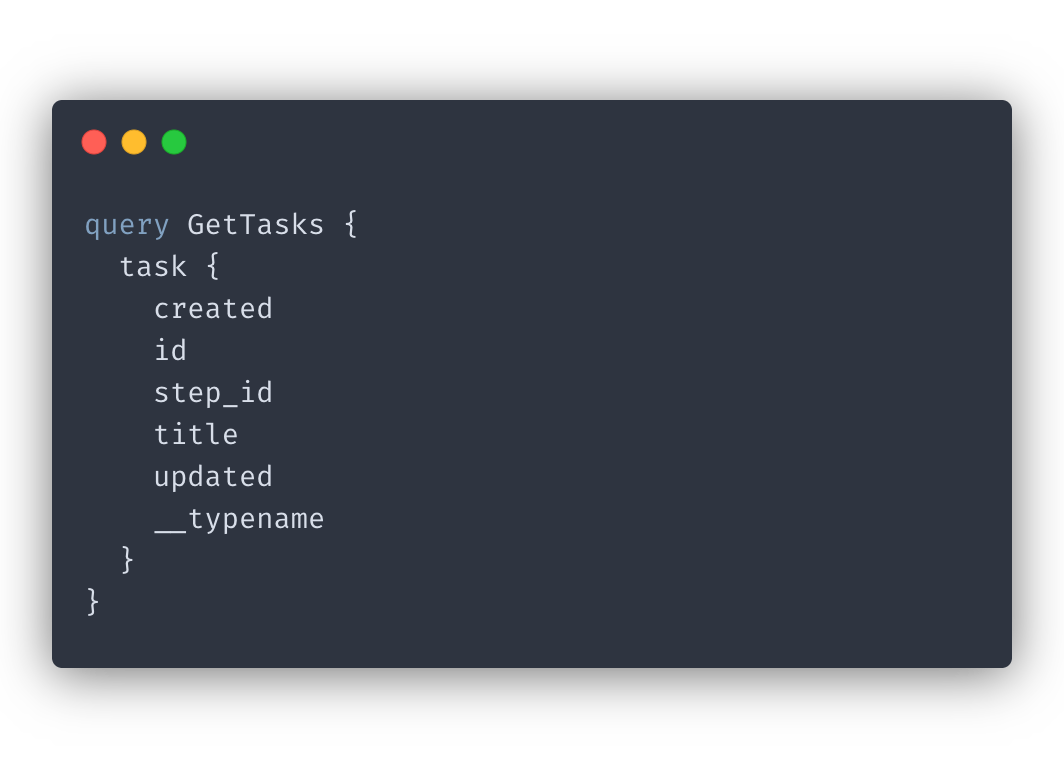
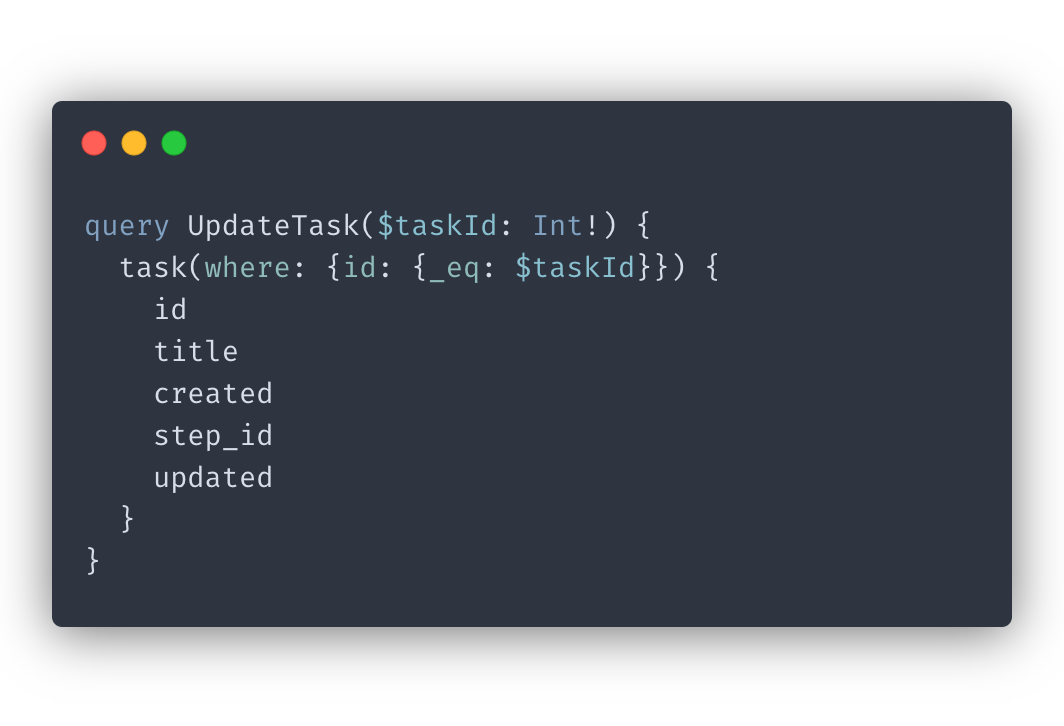
Always return id and updated data for mutations
Similarly, you should always return the id AND the updated data from your mutations if you want Apollo to cache it. This tip applies both to single mutations as well as mutating a set of objects.
Conclusion
In this post, we briefly covered how Apollo’s caching mechanism works under the hood and how to optimize your GraphQL queries to take full advantage of it and reduce the amount of redundant API calls your application makes.
If you’d like to get more web development, React and TypeScript tips consider
following me on Twitter,
where I share things as I learn them.
Happy coding!